By Sijmen J. Mulder, 25 December 2024.
December: the month of ubiquitous Christmas music and, more importantly, the Advent of Code! I’ve completed all years since 2020 so far, and with some trepidation (dread?) I stepped into this year’s challenge.
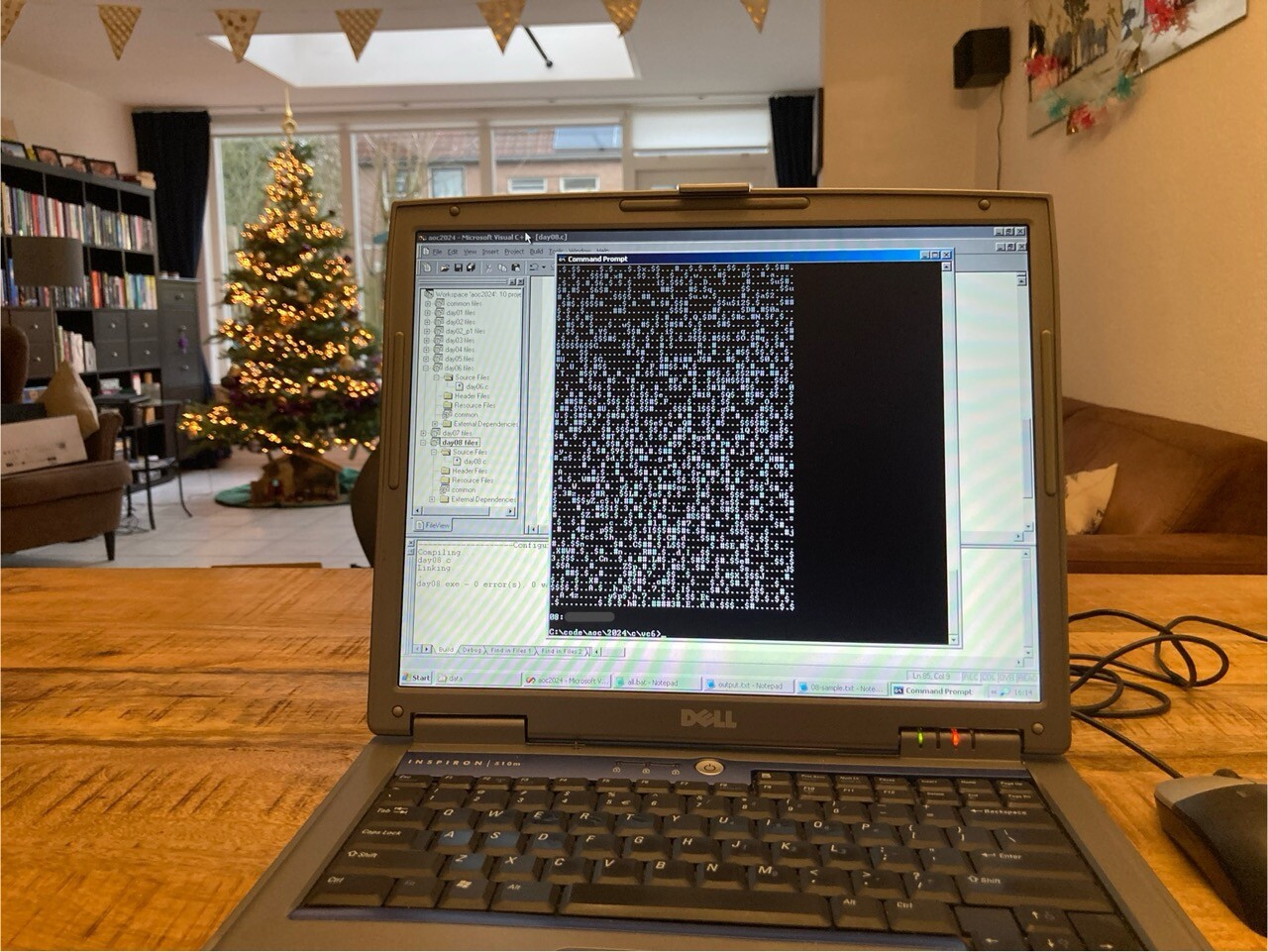
As before, I picked C as my main language, with which I’ve built up some experience over the past puzzles (more on that below). As a bonus, it’s fun to get things working on old software and hardware:
You can find all my code on Codeberg.
Most of these come from my Mastodon postings. Spoilers ahead!
Part 1 is a sort and a quick loop. Part 2 could be efficient with a lookup table but it was practically instant with a simple non-memoized scan so I left it that way.
Wrote this on an old Windows 7 laptop with Visual Studio 2013 because I couldn’t bring my normal laptop for the weekend trip!
JavaScript version with list comprehensions.
First went through the input in one pass, number by number, but unfortunately that wouldn’t fly for part 2.
JavaScript version with list comprehensions.
Yay parsers! I’ve gotten quite comfortable writing these with C. Using out pointers arguments for the cursor that are only updated if the match is successful makes for easy bookkeeping.
What can I say, bunch of for loops! I add a 3 cell border to avoid having to do bounds checking in the inner loops.
I got the question so wrong – I thought a|b and
b|c would imply a|c so I went and used dynamic
programming to propagate indirect relations through a table.
It worked beautifully but not for the input, which doesn’t
describe an absolute global ordering at all. It may well give
a|c and b|c and c|a.
Nothing can be deduced then, and nothing needs to, because all required
relations are directly specified.
The table works great though, the sort comparator is a simple 2D array index, so O(1).
Got super stumped on part 2. I’d add an obstacle for every tile on the path of part 1 but I kept getting wrong results, even after fixing some edge cases. Spent too much time looking at terminal dumps and mp4 visualisations.
Eventually I gave up and wrote a for(y) for(x) loop,
trying an obstacle in every possible tile, and that gave the correct
answer. Even that brute force took only 2.5 ish seconds on my 2015 PC!
But having that solution allowed me to narrow it down again to a
reasonably efficient version similar to what I had before. Still I
don’t know where I went wrong the first time.
Big integers and overflow checking, what else is there to say!
Working on an old laptop, the Dell Inspiron 510m, but it’s so slow that my TOTP token expired before Firefox managed to submit it!
I suspect the CPU is being throttled by Linux. lscpu
reports 35% scaling MHz while it’s under full load and on AC. But
I don’t know where to look really. Powertop isn’t showing
anything interesting.
Eventually patience paid off and I managed to get the files to the Windows XP partition and continue from there – see the photo above!
First went with a doubly linked list approach, but it was quite verbose and we’re dealing with short runs (max 9) anyway so back to the (plenty fast) flat array.
Now there’s another little thing I’ve been working on, but I haven’t got to finishing it yet:
Tried a dynamic programming kind of thing first but recursion suited the problem much better.
Part 2 seemed incompatible with my visited list representation. Then
at the office I suddenly realised I just had to skip a single
if(). Funny how that works when you let things brew in the
back of your mind.
For this one, I used my ffmpeg visualisation library to write a little visualization (code):
Started out a bit sad that this problem really seemed to call for hash tables – either for storing counts for an iterative approach, or to memoize a recursive one.
Worried that the iterative approach would have me doing problematic O(n^2) array scans I went with recursion and a plan to memoize only the first N integers in a flat array, expecting low integers to be much more frequent (and dense) than higher ones.
After making an embarrassing amount of mistakes it worked out beautifully with N=1m (testing revealed that to be about optimal). Also applied some tail recursion shortcuts where possible.
No big trouble, just a bit of careful debugging of my part 2 logic for which I was greatly helped by some Redditor’s testcase (unfortunately I do not remember who!).
Happy to have gotten it all in the single flood fill function without any extra passes
“The cheapest way” “the fewest tokens”, that evil chap Eric Wastl!
I was on a weekend trip and thought to do the puzzle in the 3h train ride but I got silly stumped on 2D line intersection, was too stubborn to look it up, and fell asleep!
The line intersection trouble was on two parts:
int64 friends don't let int64 friends play with float32s.
Solved part 1 without a grid, looked at part 2, almost spit out my coffee. Didn’t see that coming!
I used my visualisation mini-library to generate video with ffmpeg, stepped through it a bit, then thought better of it – this is a programming puzzle after all!
So I wrote a heuristic to find frames low on entropy (specifically: having many robots in the same line of column), where each record-breaking frame number was printed. That pointed right at the correct frame!
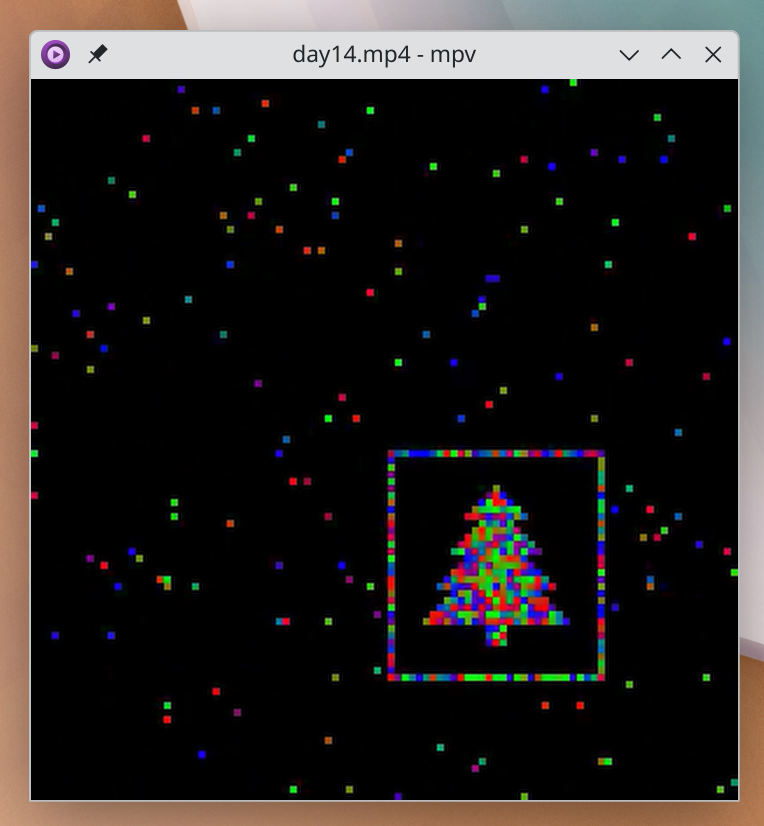
It was pretty slow though (.2 secs or such) because it required marking spots on a grid. I noticed the Christmas tree was neatly tucked into a corner, concluded that wasn't an accident, and rewrote the heuristic to check for a high concentration in a single quadrant. Other people’s output revealed that was a mistaken assumption, however, so I reverted the change.
After a 3h+ train ride back home from a weekend trip I was a little tired and not feeling it much. Finished part 1, saw that part 2 was fiddly programming, left it there.
Finally hacked together something before bed. The part 2 twist required rewriting the push function to be recursive but also a little care and debugging to get that right. Cleaned it up over lunch, happy enough with the solution!
Yay more grids! Seemed like prime Dijkstra or A* material but I went with an iterative approach instead!
I keep an array cost[y][x][dir], which is seeded at 1
for the starting location and direction. Then I keep going over the
array, seeing if any valid move (step or turn) would yield to a lower
best-known-cost for this state. It ends when a pass does not yield
changes.
This leaves us with the best-known-costs for every reachable state in
the array, including the end cell (bit we have to take the
min() of the four directions).
Part 2 was interesting: I just happened to have written a dead end pruning function for part 1 and part 2 is, really, dead-end pruning for the cost map: remove any suboptimal step, keep doing so, and you end up with only the optimal steps. ‘Suboptimal’ here is a move that yields a higher total cost than the best-known-cost for that state.
Was looking forward to a VM! Really took my leisure for part 1, writing a disassembler, tracing, all pretty.
Part 2 reminded me of 2021 day 24 where we also had to reverse an input. It’s been on my mind recently and I was thinking if there would be a way to backfeed an output through a program, yielding a representation like: ”the input plus 3498 is a multiple of 40, and divisible by a number that's 5 mod 8” (considering lossy functions like modulo and integer division).
The day’s input didn’t lend itself to that, however, but analysing it having the solution ‘click’ was very satisfying.
Flood fill for part 1. Little tired so for part 2 I just retried the flood fill every step. Slow by C standards (2s).
Properly awake, with a tip on Lemmy and a switch to recursion the runtime was quickly brought back down to a respectable 0.00 seconds on my PC!
Interestingly part 1 already defied a naive approach. It was fun thinking of a way to memoize without hash tables.
Note to self: reread the puzzle after waking up properly! I initially wrote a great solution for the wrong question (pathfinding with a given number of allowed jumps).
For the actual question, a bit boring but flood fill plus some array iteration saved the day again. Find the cost for every open tile with flood fill, then for each position and offset combination, see if that jump yields a lower cost at the destination.
For arbitrary inputs this would require eliminating the non-optimal paths, but the one path covered all open tiles.
Finally got this one done very late at night the next day or so!
I kept getting stuck reasoning about the recursion here. For some reason I got myself convinced that after a move, the state of the ‘upper’ dpads could make it more advantageous to pick one followup move over another – i.e. steps aren't independent.
It took a bunch of manually working through sequences to convince
myself that, after every move, every dpad above it would be on
A. With that, it’s ‘just’ recursive
pathfinding for independent moves.
Since there are relatively few types of moves needed on the dpad, I just sketched them out and wrote the routes in code directly (up to two options per move, e.g. left,up or up,left).
Really proud of this one! Started with with an O(n^atoms in the universe) scan which took 44s even after adding a dedup check.
But iterating on a trick to encode the deltas for the dedup check, using it to build a mapping table here, a lookup there etc brought it down to a very fast, fairly low memory, linear complexity solution!
I think integer indexing (vs set lookups) and linear iteration are lucky to be both easy to do in C and a perfect fit for CPU pipelining and memory caching!
Graph problems are not my cake but this one I could work out: recursively iterate unique combination of adjacent nodes. Performance benefits from using a basic, int-indexed adjacency matrix.
This one gave me stress.
Considered several approaches, the coolest of which would have been to test individual bits, propagate ‘suspicion’, etc, but it seemed too tricky.
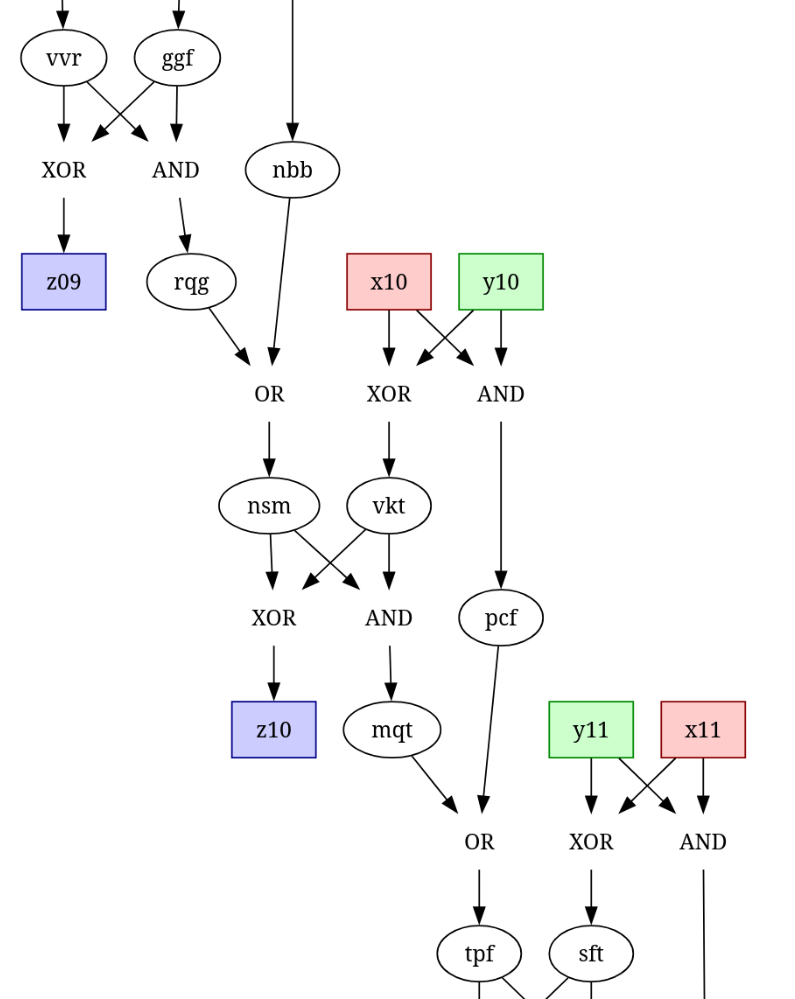
Eventually I needed to go do something other than worry about not finishing so I started writing a validator for the adder structure. Just a couple of rules later I had found 4 faults already and managed to write automated fixups for them!
This means my solver is quite specific to my input but it can potentially be made more complete and I didn’t ‘cheat’ by hardcoding manual graph analysis.
Btw, spending some time on getting Graphviz output right did make studying the structure much easier!
After a very late night finishing day 24, I got up at 6 AM anyway to get the final stars!
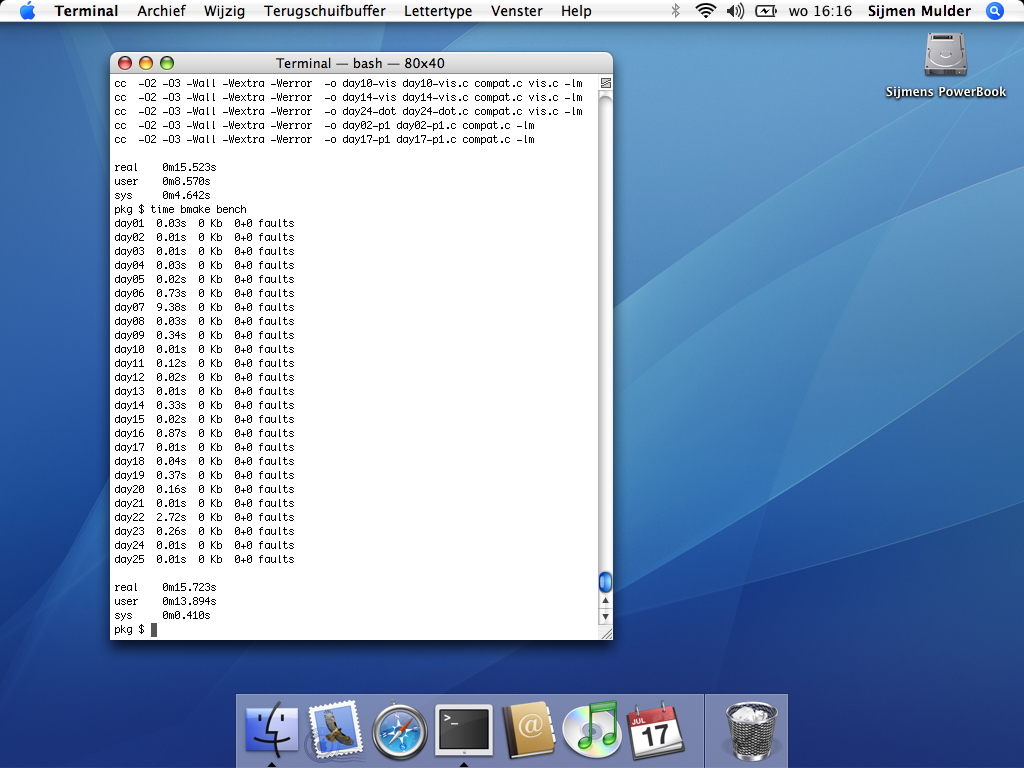
As we approached day 20, I got increasingly hopeful that I’d be able to get the 1-second challenge: having all my solutions, together, finish in less than a second. And I did! This is on my 2023 i5 laptop:
$ time bmake bench
day01 0:00.00 1912 Kb 0+88 faults
day02 0:00.00 1992 Kb 0+91 faults
day03 0:00.00 1920 Kb 0+93 faults
day04 0:00.00 1912 Kb 0+90 faults
day05 0:00.00 2156 Kb 0+91 faults
day06 0:00.03 1972 Kb 0+100 faults
day07 0:00.06 1892 Kb 0+89 faults
day08 0:00.00 1772 Kb 0+87 faults
day09 0:00.02 2024 Kb 0+137 faults
day10 0:00.00 1876 Kb 0+87 faults
day11 0:00.00 6924 Kb 0+3412 faults
day12 0:00.00 1952 Kb 0+103 faults
day13 0:00.00 1908 Kb 0+88 faults
day14 0:00.05 1944 Kb 0+92 faults
day15 0:00.00 2040 Kb 0+89 faults
day16 0:00.03 2020 Kb 0+250 faults
day17 0:00.00 1896 Kb 0+88 faults
day18 0:00.00 1952 Kb 0+107 faults
day19 0:00.01 1904 Kb 0+91 faults
day20 0:00.01 2672 Kb 0+325 faults
day21 0:00.00 1804 Kb 0+86 faults
day22 0:00.03 2528 Kb 0+371 faults
day23 0:00.02 2064 Kb 0+152 faults
day24 0:00.00 1844 Kb 0+89 faults
day25 0:00.00 1788 Kb 0+89 faults
real 0m0,359s
The 2015 PC gets it in comfortably, too. And, after a little bit of porting effort to support GCC 4, even my first-ever laptop, a 2004 PowerBook G4 with Mac OS X 10.4 Tiger runs it reasonably quickly:
Since starting to use C for Advent of Code in 2018 or so I have, through trial and error, developed a style of programming that works well for me.
As a compiled, low-level language, C is very suited for writing fast solutions. But in the end, a good algorithm will beat compiler optimisations. What I try to do, then, is make use of C’s strengths that align with efficient use of CPUs and memory caching: direct array indexing and a preference for linear access (iteration).
Some general tips:
while (fgets()) for reading input lines.while (strsep()) for splitting fields (day 5).dump() function early on to aid with
debugging, this can be text but also graphics (like in this photo).assert() liberally!Thanks for making it all the way here! Hope it was worth your while. I enjoyed solving the puzzles but, more than that, interacting with all you people online. From crazy looking Uiua code to the the amazing Advent of OS/2 with Java 1 – or what about FORTRAN 77!
In the future I’d like to play around with a language with first-class support for advanced data structures, the very opposite of my C approaches, or perhaps an array programming language like K or Uiua. And I was inspired by the author of the blog linked above to try out OS/2 and have a go at retro Java, a platform I never considered.
Thanks Eric for the puzzles!